
@inproceedings{bai2026ercsvd,
title={ERC-SVD: Error-Controlled SVD for Large Language Model Compression},
author={Bai, Haolei and Jian, Siyong and Liang, Tuo and Yin, Yu and Wang, Huan},
booktitle={CPAL},
year={2026}
}
@article{bai2025ressvd,
title={Ressvd: Residual compensated svd for large language model compression},
author={Bai, Haolei and Jian, Siyong and Liang, Tuo and Yin, Yu and Wang, Huan},
journal={arXiv preprint arXiv:2505.20112},
year={2025}
}
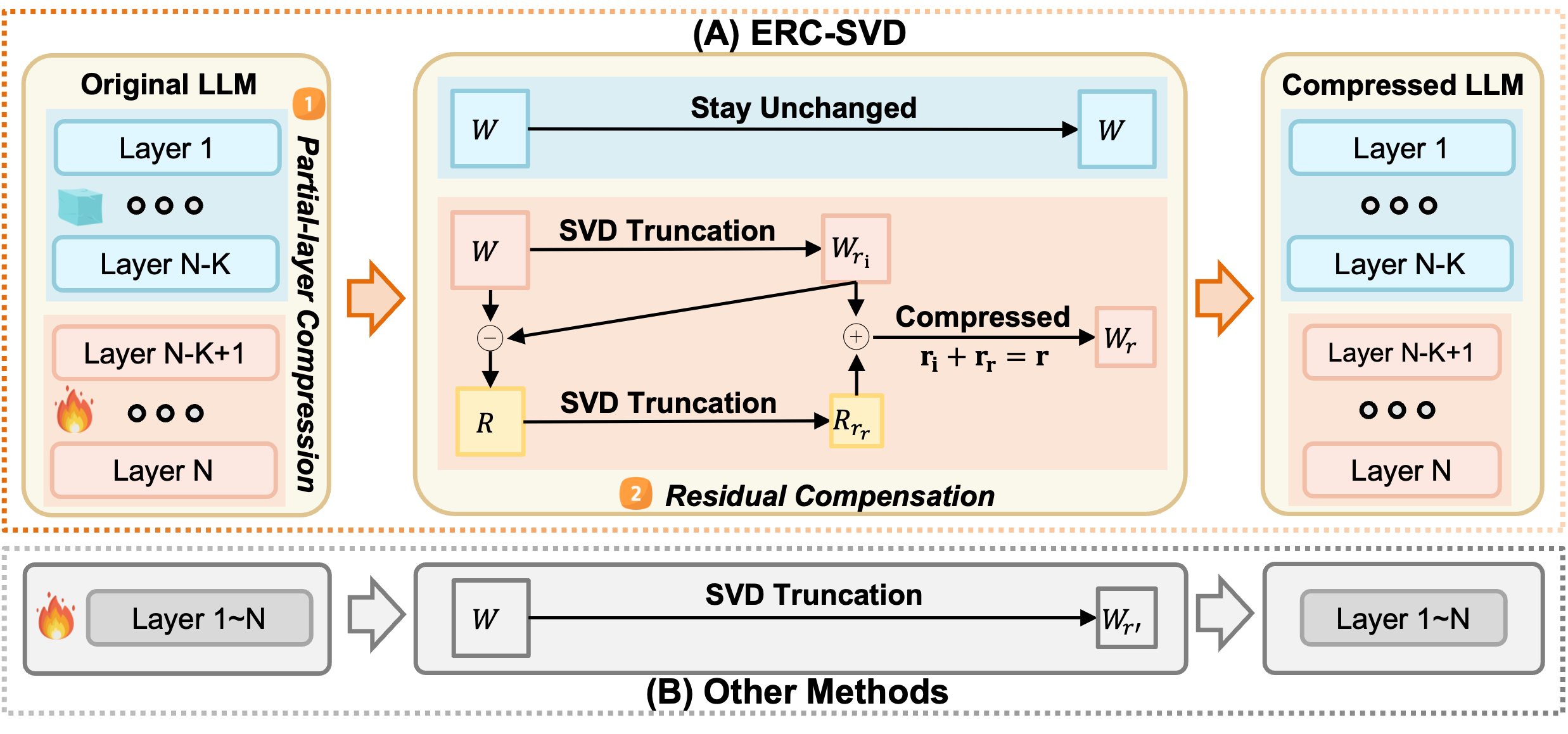
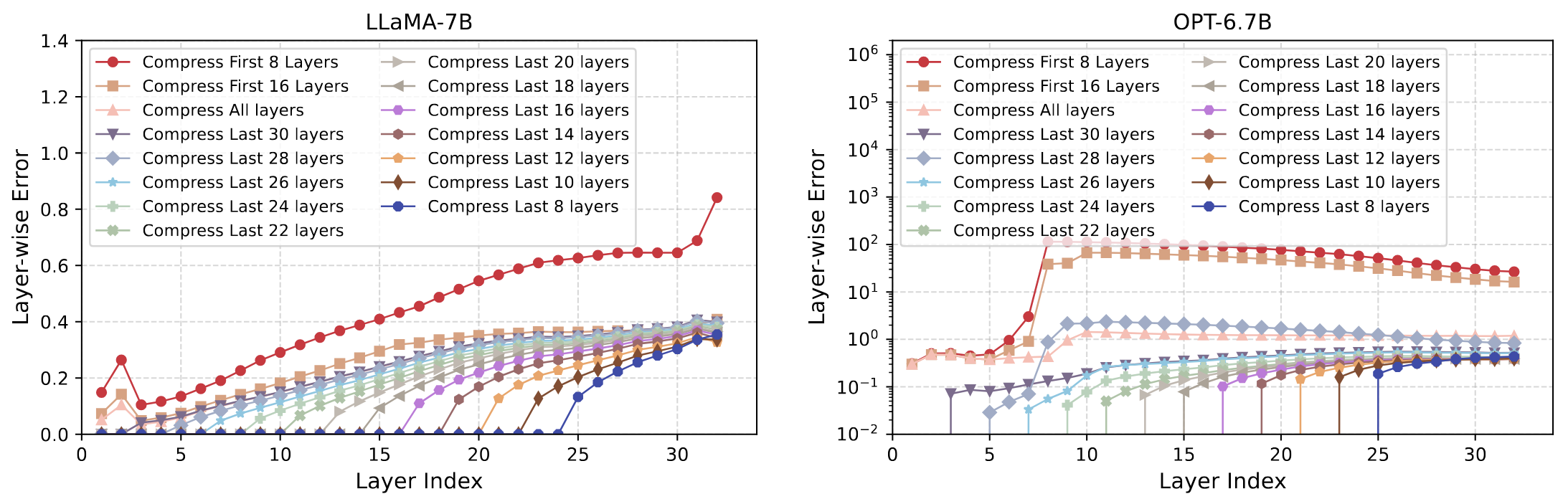
 denotes these layers remain intact, while
denotes these layers remain intact, while  denotes these layers are replaced by low-rank approximations.
The overall compression ratio is Ro, for ERC-SVD, the first (N-k) layers stay unchanged, and the layer compression ratio Rl for last k layers is (N x Ro)/k.
denotes these layers are replaced by low-rank approximations.
The overall compression ratio is Ro, for ERC-SVD, the first (N-k) layers stay unchanged, and the layer compression ratio Rl for last k layers is (N x Ro)/k.